This is the third entry in a five-part series about event sourcing:
In the first article, I introduced this series with the spark that made me so happy to finally try event sourcing.
In the last article, I showed you what event sourcing is.
In this article, I will show you how and why I’ve completely changed the way I code.
Editing software is hard
Have you ever worked on a project where adding a simple feature felt like defusing a bomb—one wrong move, and the whole system might break? You’re not alone. In 1979, the industry was reeling from how hard it was to modify software.
I came across an article from the Association for Computing Machinery 1979 that talked about a crisis in the software community: how expensive it was to modify existing software:
Another component of the software crises is less commonly recognized, but, in fact, is often more costly… namely, the extreme difficulty encountered in attempting to modify an existing program… The cost of such evolution is almost never measured, but, in at least one case, it exceeded the original development cost by a factor of 100.
Could you imagine asking a team of developers to adjust a program and having to pay 100x what you paid them to write it in the first place?
I’ve been on projects where I can start to see how this happened, but it’s crazy this is where our industry came from.
This was untenable, and many smart people discussed how to improve software writing. A lot of progress was made in the 1980s and 1990s.
One of the main discoveries was that unwanted coupling made software more complex and more challenging to refactor. This was reflected in several pieces of the time, including Martin Fowler’s curation of refactoring methods in his seminal book published in 1999 and Robert Martin’s curation of the SOLID principles in the early 2000s.
Despite these discoveries, the challenges of modifying software haven’t disappeared. Instead, they’ve taken on new forms, often exacerbated by the industry’s rapid growth.
In the 2000s, the number of developers grew explosively, and the percentage of people who knew how to teach these concepts became a tiny percentage of the population. As a result, most developers have only heard of these techniques and patterns, like SOLID, but few truly understand or practice themFor example, I’ve noted a trend of programing resumes announcing they are skilled in OOPS. .
Most developers are not familiar with or practiced in controlling complexity or refactoring to reduce unwanted coupling.
A real example
I imagine the 100x penalty for adding features to projects is a thing of the past, but I know of a project that was in trouble in a similar way.
This team struggled with slow development cycles because every feature required each developer to make changes across multiple layers, including database schema, API, UI state, and frontend components. Merge conflicts were constant, and progress slowed to a crawl. In this case, they ultimately found success by reducing complexity and shifting their React front end to HTMX.
But switching frameworks isn’t always an option. A deeper change is needed: a way to structure software that naturally reduces coupling.
One solution is to continue to educate people about refactoring, software patterns, and good habits—and define times to practice these new skills. I’ve been impressed with Emily Bache’s Samman Technical Coaching Society approach, which truly gives developers the space to learn and practice these skills on their codebase as a team.
I believe the Samman Society and other like-minded technical coaches are making an impact in the industry. But they can only work with so many teams. What if we could fundamentally change how we structure our applications to reduce this complexity at its source?
In the last few months, I’ve been convinced that there’s another option: changing how we write apps to reduce coupling.
What is coupling?
The excellent book Cosmic Python (aka Architecture Patterns in Python) explains coupling in this way:
In a large-scale system, we become constrained by the decisions made elsewhere in the system. When we’re unable to change component A for fear of breaking component B, we say that the components have become coupled. Locally, coupling is a good thing: it’s a sign that our code is working together, each component supporting the others, all of them fitting in place like the gears of a watch. In jargon, we say this works when there is high _cohesion_ between the coupled elements. Globally, coupling is a nuisance: it increases the risk and the cost of changing our code, sometimes to the point where we feel unable to make any changes at all. This is the problem with the Ball of Mud pattern: as the application grows, if we’re unable to prevent coupling between elements that have no cohesion, that coupling increases superlinearly until we are no longer able to effectively change our systems.
Unwanted coupling is easy to accidentally introduce into your application. Most of the time, we couple things together because it seems like a good idea at the time. We don’t know if it’s unwanted until some time in the future.
One way to tell if your code has unwanted coupling is to test it. If the test case is easy to make, you probably have an healthy level of coupling. Testing is the canary in the coal mine for coupling.
Before I understood how to deal with coupling, I watched it take over on one project, where a function grew day after day, as we added new features to it, trying to meet a deadline. It started out processing some data. Then, we needed to add a feature to notify people when it finished. That was followed by some additional processing requirements and API calls to augment data. We also decided to add code to notify us if something failed in some of these steps.
What started out as a relatively simple function turned into over 100 lines of code with several different workflows braided together. I could tell something was off by the number of parameters we had and how hard it was to test, but I had no idea how to unwind it.
How to reduce coupling
So how do we reduce unwanted coupling? I mentioned above that one way is to learn how to make great software, how to refactor it, and practice it many times outside of normal project work.
In the last year, I’ve come across articles, podcasts and videos that has convinced me to change the way I work to help keep coupling low.
There are three key practices work together to keep complexity under control while enabling flexible and scalable solutions: event modeling, vertical slice architecture, and event sourcing.
Let’s look at these one at a time.
Event modeling
Event modeling is a documentation method that shows how data flows through a system and the domain constraints in play.
It might seem weird to start off with a documentation method, but by starting with getting the developers on the same page as the business stakeholders, you eliminate many surprises, and get a few more benefits.
Event modeling grew from event storming, a documentation workshop technique that extracts complex business domains from stakeholders and transforms them into domain-driven design concepts that developers can use.
As a user of event storming, Adam Dymitruk noticed that business stakeholders were left behind During event storming sessions once the conversation became more about bounded contexts and other technical implementation details.
After many iterations, he unveiled event modeling in 2020. It’s a documentation method that removes much of the implementation detail. Instead, it highlights the most important thing: data, and how it enters, gets used by, and exits the system, as well as domain rules that affect it, all in a simple visual language with four patterns to master.
Additionally, the application’s lifecycle is segmented into individual slices representing one process step. Each slice maps to a slice in the vertical slice architecture that we’ll discuss below.
Below is an example event modeling diagram showing part of the lifecycle of a shopping cart application. The blue boxes are commands. They represent an intent to change the state of the system. This is where domain rules are enforced, and a command either generates an event or an exception.
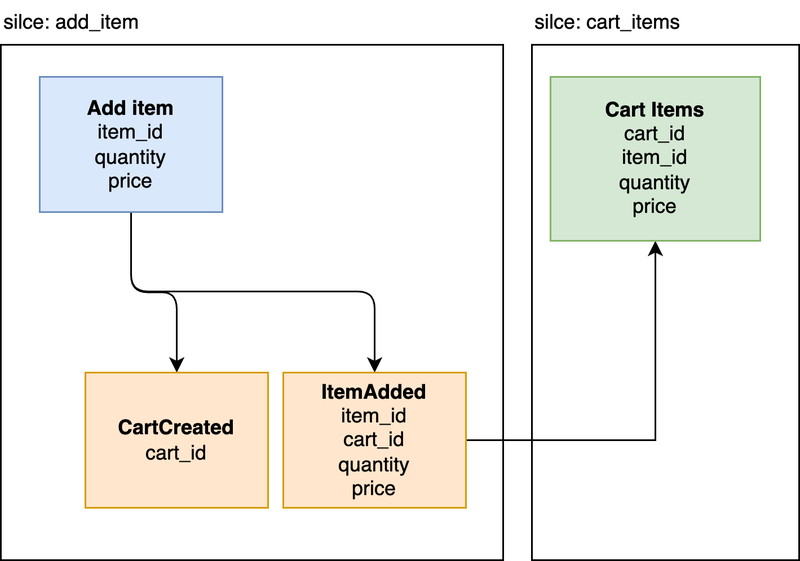
By creating an event, this changes the state of the system. Other slices listen to events and populate views (the green boxes). These can be caches, database tables, CSV files, or anything that formats data in a way that will be consumed.
Having done a couple event modeling diagrams, what I like about them are:
- Being able to understand the domain more as the diagram comes together
- Uncovering needs early in an project, instead of late in the process when you’re implementing the feature under time pressure.
- Making it easier for everyone—developers and stakeholders—to stay aligned
Vertical slice architecture
I’ve been conditioned by the majority of my projects and more senior teammates to expect the projects I work on to be organized with similar code together. The views, services, and models would be grouped by type and placed into a folder bearing its name.
Contrasting this practice, vertical slice architecture organized code by feature. For example, if we’re working on a shopping cart application. A vertically-sliced project would have folders with names like add_item , checkout , remove_item , and list_items .
In each of these folders, you would find the UI, data access code, and business logic related to those features.
I’ve found this to be a great way to work. Instead of hunting around the project or tracing through the code from the endpoint down into every layer that gets called, I can just open the folder for the feature and have a very good idea what file to open.
Adam Dymitruk’s group has seen great productivity increases from adopting vertical slice architecture. He’s mentioned having ten developers working independently on slices and not having a single merge conflict.
When all the code for a feature is in one folder, suddenly adding a feature to a “normal” project feels like performing shotgun surgery.
I like a lot about object-oriented programming, especially with an imperative shell and a functional core. With well-designed OOP software, you can trust that by editing one part of the code, you won’t introduce a bug in another part. It seems I’ve never worked on well-designed OOP code—or I’m just that good at finding the weak spots of our designs.
Putting it all together with event sourcing
With an event modeling diagram and the direction to implement a specific vertical slice, a developer can concentrate on what data is entering their slice (whether from the user, an external provider, a read model, or by subscribing to events), handle the business case, and then publish the events expected from their slice or populate a database table as needed.
A event-sourced project with vertical slice architecture, each slice is isolated from the other, communicating through predefined events and views. It’s a really cool pattern.
Caveat
It’s important to note that you could reduce coupling without event sourcing. Communicating well with event modeling diagrams and an even-driven, vertically sliced architecture, you can have similar gains.
The three practices together have proved powerful for me. In the next article, I’ll show you more detail how, while also having the benefits of an event-driven microservice and a monolith.